
Key ideas for fast flow and DevOps transformation - from DevOpsDays Oslo 2023

The start of DevOpsDays Oslo 2023 - photo by Lena Sellberg
Key points:
The community feel and 50:50 gender balance helped to make DevOpsDays Oslo a wonderful event.
Beware of fixing platform boundaries accidentally when using Infrastructure-as-Code tools, and instead be mindful of the effect of different config and code styles on the Dev and Ops split.
Group trust boundaries are very real and may have fundamental roots in physical dynamics (relating to energy): for fast flow, a team size of 8 people is probably best.
Adopting Team Topologies and fast flow in general needs significant investment in awareness, techniques, practices, and mindset. It’s not a 3-week tweak to team names.
DevOpsDays Oslo 2023 was an exemplary conference

The opening of DevOpsDays Oslo 2023 - Mike Long and Elin Brusberg - photo by Lena Sellberg (https://bedriftsfotografering.photoshelter.com/index)
I think DevOpsDays Oslo was one of the best conferences I have been to as an attendee in at least 10 years. I don’t know whether the organizers read my 2018 blog post on How to run a good tech conference, but the conference had all the key things that a good conference needs:
A fabulous organizing team: the organizing team had a ratio of around 50:50 women:men, leading to a decent balance of attendees and speakers.
A great venue: the venue (Sentralen) is a former bank with high ceilings and marble columns, giving enough space in the main hall for all the Open Space sessions to happen together. This was a really special, inclusive feeling.
A practitioner-led event: the event was not-for-profit and had a great community feel to it. The sponsors were not pushy.
An inclusive feel: the lightning talks and open space sessions gave room for people new to speaking & participating.
Good sponsors and suppliers: the sound and video were amazing quality because the venue normally hosts music events. This made a big difference compared to conferences held in hotels or mediocre conference venues. The orange t-shirts were very distinctive, with the Oslo tiger prominent, giving a feeling of pride in the local tech scene.
Not-for-profit: the conference felt better for not having profit as a motive.
Smooth ticketing and check-in: using the ticketing options from Tito made the check-in easy.
Treat everyone with respect: the Code of Conduct was emphasized early on, and because there were only about 170 attendees, it felt quite intimate, with no “stochastic jerk” behavior that happens at larger conferences.
Great keynote speakers: I’m biased of course (!), but the mix and range of topics from the keynote speakers seemed really good.
Overall, it was great to see the DevOpsDays format and “feel” still going strong after so many years. Kudos to the people in the core DevOpsDays team who help to make each DevOpsDays event a success.
The same old Infrastructure-as-Code tooling problems will recur (unless we solve the Dev and Ops split)
Kat Cosgrove gave a tour-de-force journey back in time to discover the roots of infrastructure-as-code (IaC) via configuration management, starting with make and PXE boot and then via CFengine to Puppet, Chef, and Ansible (when cloud came along), and more recently to modern day Terraform, CDK and Pulumi to deal with containers and Kubernetes (and more).

Kat Cosgrove at DevOpsDays Oslo explaining the history of Infrastructure-as-Code
Kat made a crucial point that many of these tools chose to “pick a side” between Developers (who prefer a syntax that smells like code) and Operations people (who prefer a syntax that smells like configuration). Clearly, neither code nor config is inherently “righter” but choice of syntax acted to cause splits in the use of the tools. For example, Puppet was/is more config-like than Chef and so Puppet users tend[ed] to be Ops-y people, whereas Chef’s syntax is/was more Ruby-like, so attracted Developer-y people.
“Turns out letting computers talk to each other created a lot of work for us. Oops.”

Kat Cosgrove at DevOpsDays Oslo explaining the history of Infrastructure-as-Code: “Turns out letting computers talk to each other created a lot of work for us. Oops.”
The danger here is that the “stack” is defined primarily by how suitable the syntax is for a particular group, not by the needs of the teams. In my subjective experience, around 50.273%* of problems in IT and software delivery stem from inflexibility around the “platform boundary” in a given situation. Companies like Airbnb spent significant engineering effort to turn a raw, out-of-the-box technology into something usable by engineers.
*I invented this number, but the % is substantial.
Kat and I were chatting later that day, and we talked about the real need for tools that enable the “break in the stack” - the division between “platform” (in a Team Topologies sense) and “application” - being flexible and changeable. Imagine something like Pulumi but where you can define a “platform” boundary where the config-like syntax ends and then code-like syntax takes over above that point. And importantly, that boundary can be configurable per application or service that runs on the platform. That would be an awesome tool.

Hand-drawn sketch of a shifting “platform boundary” that adjusts over time to suit the needs of flow and team cognitive load.
I liked how Kat made all the concepts around IaC so straightforward and accessible without losing any nuance or detail, and I loved the connection to the human experience (dev vs Ops) rather than obsessing about the technical details (of course, as a core contributor to key Kubernetes code, Kat knows the tech details very well indeed, but she doesn’t need to shout about that knowledge, which is refreshing).
Trust is fundamentally about attention energy - insights from physics and Wikipedia
Mark Burgess has been a leading thinker and innovator in the IT and computer science space for decades. In fact, he led the team that developed the first widely-adopted configuration management tool, CFengine back in the 1990s. In his keynote talk, Mark explained some research he has been doing around trust.

Mark Burgess at DevOpsDays Oslo 2023 - speaking about trust as energy flows
It turns out that trust can actually be modeled with well-known equations from physics concerning potential energy and kinetic energy. Distrust is actually a kinetic thing: if we distrust something, we pay lots of attention to it (expend lots of energy) whereas if we trust something, we expend very little energy on it. Interestingly, for high trust to be maintained, we actually need a mission (or in prehistoric times or periods of conflict even a threat) to bring us together.
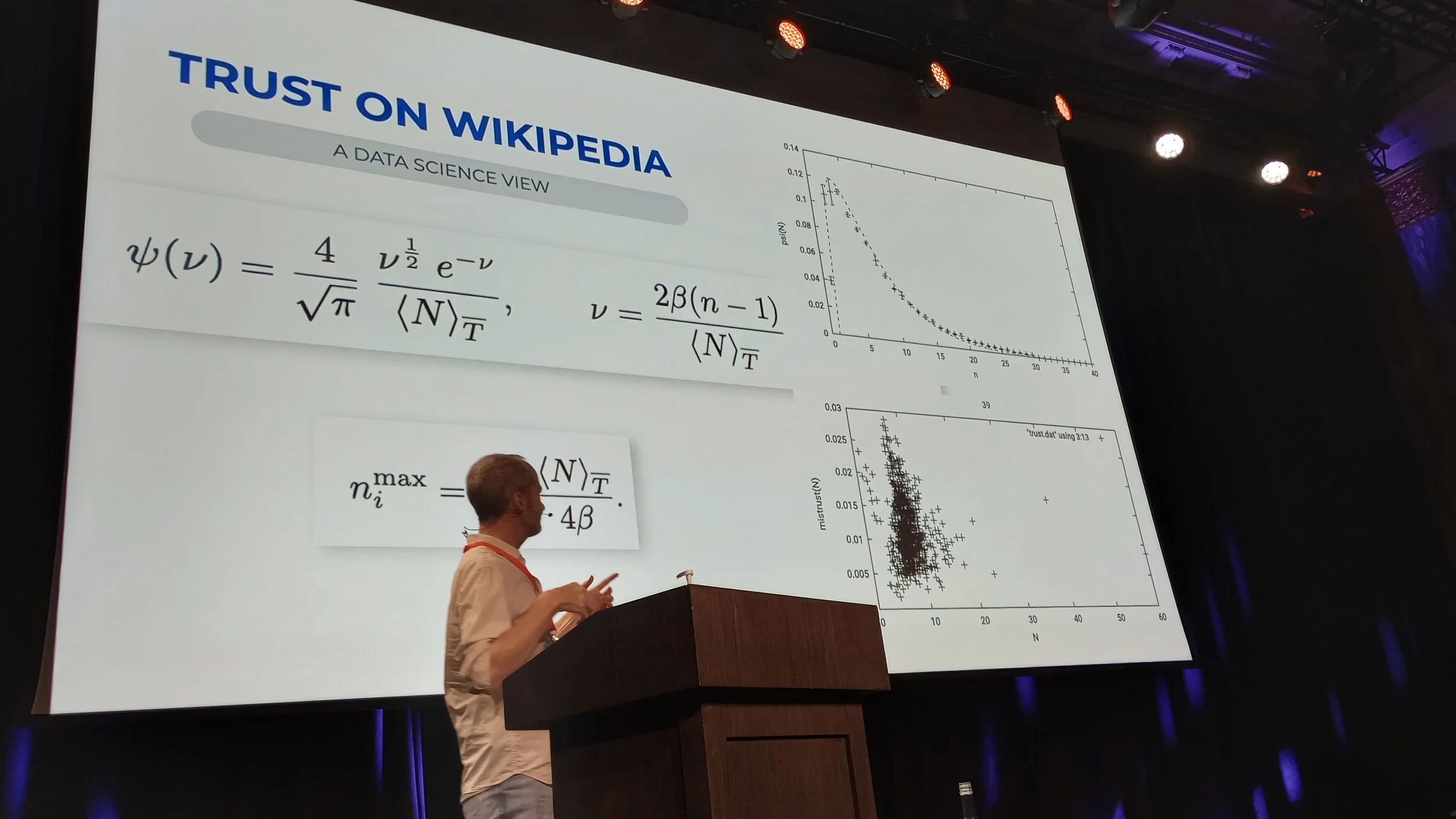
Mark Burgess exploring some research he did on trust boundaries around edits on Wikipedia. There is a strong boundary at n=8 group size.
Mark described some research he did on Wikipedia editing patterns across more than 200k edits that showed a very strong group size effect at around 8 people. Effectively, 8 people is the largest group size where humans can collaborate with high intensity to find high social cohesion. This underlying trust dynamic is why we recommend small teams of up to about 8 people in Team Topologies; high trust means a team can make decisions very quickly, essential in a fast flow environment.
The research into Wikipedia edits will be published together with Professor Robin Dunbar as a co-author as Group Related Phenomena in Wikipedia Edits.
Team Topologies is not about structure but dynamics… and is a significant change for most organizations
I was really pleased to give the opening keynote talk at DevOpsDays Oslo 2023 because it was almost exactly 4 years since the publication of my book Team Topologies (TT) in September 2019. This meant I had the opportunity to reflect on what I and my colleagues have learnt since then, working with hundreds of organizations around the world.
Since the TT book was published, I have come to realize that TT is not really a framework or model but instead: Team Topologies is a set of constraints to encourage emergent behaviors for fast flow.
Team Topologies is a set of constraints to encourage emergent behaviors for fast flow.
Seeing TT as a set of constraints helps to focus on the emergent behavior that we might want in a fast flow context: continuous adjustment of service and team boundaries, attention to the team cognitive load across all parts of the organization, listening for early signals (leading indicators) that flow is blocked, and so forth.

Matthew Skelton giving the opening keynote at DevOpsDays Oslo 2023 = “ecosystem engineering” - photo by Lena Sellberg (https://bedriftsfotografering.photoshelter.com/index)
In my view, there are at least seven ways that organizations fail at Team Topologies and fast flow more generally, and I outlined these one-by-one in my talk:
Expecting the changes to take “about 3 weeks”: moving to fast flow is a long-term investment in a new, flow-centric operating model, not just a kind of reassignment of teams and “human resources”.
Expecting the amount of learning to be small: switching to flow-centric ways of working needs a large investment in awareness & skills, and significant reassignment of roles from “managing” to “enabling flow”.
Seeing the solution as “structure”, not org dynamics: too many execs and managers obsess about “structure”, thinking that the right structure” will magically solve all their problems. In reality, structure is something that emerges from the constraints needed for fast flow, and success comes partly from paying attention to the inter-team and inter-department dynamics (using the 3 team interaction modes from TT, for example).
Making a ;big bang’ change: changes for flow need to be made incrementally to allow learning and awareness to increase, not in a massive “re-org” that destroys trust.
Coupling things together for ease of management: often, management tries to optimize for making things easy to manage, coupling things together that are logically separate. Instead, most things need to be decoupled to enable fast flow, allowing the composite value to emerge after the different aspects are available.
Seeking “following orders” rather than empowered people: true empowerment is very unfamiliar to many organizations. Guardrails and sensible metrics help, but execs and managers also need to see the true value in empowerment: rapid discovery and innovation.
Not having the right foundations and skills: we’ve seen organizations try to adopt Team Topologies without the underlying foundations of techniques like Continuous Delivery or without any sense of psychological safety in place. These attempts will probably fail without the practices that predict high performance that we know from Accelerate/DORA.
In the context of fast flow, many principles and practices seem weird to those used to a slower pace: in fast flow, we are happy with duplication, (a few) different versions of things, asynchronous communication plus eventual consistency, an ‘internal marketplace’, and so on.
In the context of fast flow, many principles and practices seem weird to those used to a slower pace: in fast flow, we are happy with duplication, (a few) different versions of things, asynchronous communication plus eventual consistency, an ‘internal marketplace’, and so on.

The Open Space discussion on Team Topologies at DevOpsDays Oslo 2023 - photo by Lena Sellberg (https://bedriftsfotografering.photoshelter.com/index)

The whiteboard from the Open Space session on Team Topologies: Boundaryless, Haier, Humanocracy / expect boundaries to change continuously / Enabling teams should not be a “support” for Stream-aligned teams / Team API to help define expectations / Use techniques to understand purpose: JTBD, User Needs Mapping, Independent Service Heuristics, Team Interaction Modeling.
In the afternoon, there were several Open Space sessions on all kinds of topics, chosen by the attendees. I hosted one of the discussions (focused on Team Topologies) and there were some really interesting discussions. We talked about:
The use of “internal markets” inside organizations, not for buying and selling, but for speed of innovation: allowing more than one internal provider to generate some healthy competition for good approaches.
The Rendanheyi approach to running and scaling organizations (as used by Chinese megacorp Haier) and popularized in the West by organization innovators such as Boundaryless. The 12-person micro-enterprises that make up Haier are effectively extreme cases of empowered, autonomous teams.
The use of group insights to find and re-find good boundaries for fast flow: things like Independent Service Heuristics (ISH), User Needs Mapping (UNM), and Team Interaction Modeling (TIM). I explained how we have been using these techniques to really good effect inside many organizations, but that some companies find it very strange to empower teams to discover good boundaries (and those companies are likely to fail at fast flow).
I love the Open Space format. It would be great to see Open Space being used not just at great conferences like DevOpsDays but also inside organizations to help reduce hierarchy and speed discovery & innovation.
Summary: pay attention to group dynamics for effective transformation
The common theme that emerged from the sessions I attended is really that structure is not going to save or fix your digital transformation. Instead, we need to pay attention to the group sizes, group interactions, and group experience when using tools. This is really classic DevOps stuff, hinted at in my DevOps Topologies patterns from 2013 (from where some of the ideas in Team Topologies came), but many organizations and people seem to be unfamiliar with the early learnings from the DevOps movement (nearly 15 years ago as I write this).
Maybe it’s time to revisit and relearn some of the core Dev + Ops collaboration things from 10-15 years ago?
